神的时代已离去 神的故事却化为传说 流落凡间 供凡人传颂、膜拜
这是什么
在上世纪 90 年代,出现过一款不可思议的游戏——雷神之锤(Quake series)。除了优秀的情节设定和精美的画面,最让人称道的莫过于它的运行效率——要知道在那个计算机配置低下的时代,一段小动画都是一个奇迹,但 Quake 却能流畅地运行于各种配置的电脑上。
直至 2005 年,当 Quake Engine 开源时,Quake 系列的秘密才被揭开。在代码库中,人们发现了许多堪称神来之笔的算法。它们以极其变态的高效率,压榨着计算机的性能,进而才支撑起了 90 年代 3D 游戏的传奇。其中的某些算法,甚至比系统原生的实现还要快!
我们今天的主角——快速平方根倒数算法(Fast Inverse Square Root)就是其中一个。
这是一个用于计算 $1 \over {\sqrt x}$ 的算法。这是一步重要的运算,因为在 3D 绘图中,计算机需要大量求解一个矢量的方向矢量,平方根倒数为其中的一步($(v_x,v_y, v_z) \over {\sqrt{v_x^2+v_y^2+v_z^2}})$),而且为最麻烦的一步。如果能在此作优化,渲染效率无异会极大地提高。
然而,高效并不是它的唯一特点,吸引人们的更是其中的一个神秘的常数——$(5f3759df)_{16}$。
且看代码:
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}
翻译成数学语言就是:
- 设输入数为 $number$,令 $ x_2=number/2, y=number $。
- 上式中,$y$ 是一个 32 位浮点数(可以理解为数学中的实数),现在我们将其“看作”一个整数,并赋给 $i$。
- 最神奇的一步出现了——用一个十六进制数 $5f3759df$ 减去 $i$ 自身右移一位的结果,并将结果赋给 $i$。
- 将整数 $i$ 重新“看作”是一个浮点数,并赋值给 $y$。
- 令 $y=y(1.5-x_2 \times y^2)$。
- 重复一遍操作 5(事实上这一步可以忽略)。
在此需要向无计算机基础的朋友解释一下:
- 右移(Right Shifting)指的是:将一个数表示成二进制之后整体向右移动一位,并抹去溢出的末位。如 $(4)_{10} >> 1=(100)_2 >> 1=(10)_2=(2)_{10}$。其效果等价为整除 2,但由于有 CPU 指令直接支持,速度比整除快若干个数量级。
- 无论是实数还是整数,在计算机中只不过是一串二进制序列。因此一串二进制序列,既可以被看作一个实数,也可以被看作一个整数。
这个算法得到的只是一个近似值。对于 $[0.01, max\_float]$ 内的所有浮点数,最大误差为 $0.175%$(见 Accuracy)。但它却比内置算法 1.0/sqrt(x) 快 4 倍,可谓瑕不掩瑜。
那么,它究竟是怎么实现的呢?
牛顿法
我们从后面开始分析。
从代码中可以看出:算法最后有两步相同的操作,像是在对一个数进行某种迭代。而其中的第二步被注释掉了,似乎是因为和性能损耗相比对结果的二次迭代意义不大,也说明 一次迭代的结果在误差允许范围内——这让人想到了牛顿法。
牛顿法是什么?
牛顿法是一种常用的求方程数值解的方法。其叙述如下:
若在某个区间 $I$ 中,$f(x)$ 连续可导,且有唯一零点 $x_0$,则任取 $x_1 \in I$,定义数列 $x_{n+1}=x_n-{f(x_n) \over {f'(x_n)}}$,则有 $lim_{n \to \infty}{x_n}=x_0$。
用牛顿法进行迭代,可以完成对解任意精度的数值逼近。下面我们尝试写出 $x={1 \over {\sqrt {a}}}$的迭代式。
令 $f(x)={ {1 \over x^2}-a}$,则有
$$ x\_{n+1}=x_n-{f(x_n) \over {f'(x_n)}} $$ $$ =x_n-{ { {1 \over x_n^2} -a} \over {-2 \over {x_n^3} } } $$ $$ ={3 \over 2}x_n - { {ax_n^3} \over 2} $$ $$ ={x_n}(1.5-{a \over 2}x_n^2)$$
如果我们将$x_{n+1}$、$x_n$替换成$y$,将$a \over 2$替换成$x2$,可以发现和算法的最后一步是吻合的。由此可知:算法的最后确实采用了牛顿法。
也许你注意到:能解出 $1 \over {\sqrt a}$ 的方程不止这一条,迭代式的形式有很多。事实上,作者有意选择了这条方程——因为只有从这条方程得出的迭代式是 不用除法的。除法的性能十分糟糕,应该尽量避免。
但是,牛顿法不是需要迭代多次的吗?怎么在这里只进行一次就足够精确了呢?
牛顿法的收敛过程依赖于初值$x_1$的选取。若想一步到位,除非初值本身已经足够精确了。
初值是什么?
就是那神奇的第 3 步得到的结果。
神奇的 0x5f3759df
这是整个算法的奥妙所在。我们再来回顾一下:
- 上式中,$y$ 是一个 32 位浮点数(可以理解为数学中的实数),现在我们将其“看作”一个整数,并赋给 $i$。
- 最神奇的一步出现了——用一个十六进制数 $5f3759df$ 减去 $i$ 自身右移一位的结果,并将结果赋给 $i$。
- 将整数 $i$ 重新“看作”是一个浮点数,并赋值给 $y$。
有了上一节的分析,几乎可以肯定:这是为了得到 $1 \over {\sqrt {number} }$ 的一个粗略值,即应该有 $y \approx {1 \over {\sqrt {number} } }$。
为了进一步的论证,我们首先要了解一个知识点:
IEEE 754(浮点数储存标准)
IEEE 754: Standard for Binary Floating-Point Arithmetic
IEEE floating point - Wikipedia
这是计算机内实数的储存标准。
在本算法中,我们使用的是 32 位浮点数(即 用 32 个二进制位表示一个实数)。储存方式如下:
对任意一个实数 $x$,总可以将其分解为如下形式: $$ x=2^E \times (1+M)\ (E \in Z,M \in [0, 1))$$ 则 32 个二进制位安排如下: $$ S,EEEEEEEE,MMMMMMMMMMMMMMMMMMMMMM $$
- 首位为符号位,取
0为正数,取1为负数- 接下来 8 位为 带符号 指数。根据带符号数的储存方式,该数减去 127 才为真实的指数 $E$
- 接下来 23 位为底数。是 $M$ 左移 23 位再取整的结果
举个例子:将 $0.15625=(0.00101)_2$ 换算成浮点数:
$$ 0.15625=+2^{-3}\times(1+0.25) $$
则有:
- 符号位为 $0$
- $E=-3$,换算成带符号正数为 $-3+127=124=(01111100)_2$
- $M=0.25=(0.01)_2$,左移 23 位后为 $(01000000000000000000000)_2$
从而浮点表示为:$0,01111100,01000000000000000000000$
回到原题
现在,让我们思考一下:
如何只用加、减、乘和位运算神出鬼没地快速逼近 $1 \over {\sqrt x}$?
若想回答这个问题,得看我们对 $x$ 了解多少。
从上一小节的浮点数标准可以看出:计算机看到的 x 和我们接触的 x 结构不同,早在程序的编译期,$x$ 就被拆成了指数和底数两部分,并被打包存好——这一步是不耗时间的,但却给我们提供了海量的信息。
等等!指数和底数!似乎在暗示着什么!
我们,是不是可以通过对数进行运算?
设想,如果我们能利用以上信息,轻易地转换 $x$ 和 $\log_2 x$,由 $\log_2 {1 \over {\sqrt x}}={-{1 \over 2}}{\log_2 x}$ 就可以求得 $1 \over {\sqrt x}$ 的值了。
那么,$\log_2 x$ 该如何表示呢?且看以下变换。
根据 IEEE 754,对于一个 $x=2^E \times (1+M)>0$,如果我们将其 32 位浮点表示看作一个 32 位整数 $I$,则有
$$I=2^{23}\times (E+127)+2^{23}\times M$$ $$=2^{23}\times (E+127+M)$$
这个 $I$ 为已知量。通过已知量 $I$,我们可以得到已知量 $E+M$。
而另一方面,
$$ \log_2 x=\log_2 {2^E \times (1+M)} $$ $$ = E + \log_2(1+M) $$
记
$$ F(M) = M $$ $$ G(M) = \log_2(1+M) $$
注意到:当 $M\in[0,1)$ 时,$G(M)\in[0,1)$。同时观察图像可以发现 $G(M)$ 在此区间接近线性。
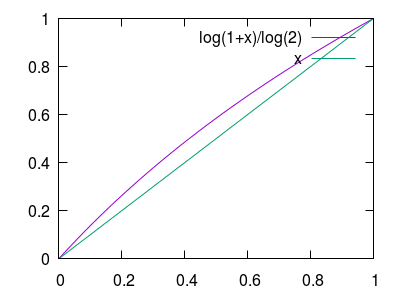
因此,我们可以通过上下移动 $F(M)$ 对 $G(M)$ 进行线性拟合。
注意一下这个例子中的误差衡量标准:我们在尽量减小误差的同时,也要保证误差分布尽量均匀,从而最大误差要尽量小。
综合以上考虑,问题最终化简为:
找到一个$\sigma$,对$\Delta(M)=\log_2(1+M)-(M+\sigma)$,使$|\Delta(M)|$在 $[0,1)$ 上的最大值尽量小。
易知:$|\Delta(0)|=|\Delta(1)|=\sigma$,另一个可能的极值点$M_0$满足$\Delta'(M_0)=0$,解得$M_0={1\over \ln 2}$
当 $max\{|\Delta(M)|\}$ 最小时,必有:$\Delta(M_0)=\sigma$。解得 $\sigma=0.0430356660279671$。
从而我们有:$ \log_2 (1+M) \approx M+\sigma $。进而:
$$ I=2^{23}\times(E+M+127)$$ $$ = 2^{23}\times(127+E+M+\sigma-\sigma)$$ $$ \approx 2^{23}\times(127-\sigma+(E+\log_2(1+M)))$$ $$ = 2^{23}\times(127-\sigma+\log_2 x)$$
则有:
$$ {I \over 2^{23}} + \sigma - 127 \approx \log_2 x $$
记 $r={1 \over {\sqrt x} }$ 对应的 $I$ 值为 $I_r$。则:
$$ I*r \approx 2^{23}\times(127-\sigma+\log_2 m)$$ $$ = 2^{23}\times(127-\sigma-{1 \over 2}{\log_2 x})$$ $$ \approx 2^{23}\times(127-\sigma-{1 \over 2}({I \over 2^{23}} + \sigma - 127))$$ $$ = (127-\sigma)\times 2^{22} \times 3-{I \over 2}$$ $$ = (5f37bcb6)*{16}-{I \over 2}$$ $$ = (5f37bcb6)\_{16}-(I >> 1)$$
这便是步骤 3 的那个式子,神秘的常数终于出现了。
这里算得的常数和原算法有一些不同,主要是 $\sigma$ 取值差异造成的。如果我们取 $\sigma= 0.0450466$ 就会得到原算法的常数。作者选取了后者,应该是综合考虑了牛顿法迭代产生的误差。我没有深入研究——事实上,在允许范围内微调 $\sigma$ 不会对精度和速度产生显著影响。
Lomont 的另一种诠释
尽管 Quake Engine 的源码直到 2005 年才被公开,这个算法却在 2000 年左右即为人们所知。2003 年,数学家 Chris Lomont 曾写过一篇 论文讨论过这一常数的由来。他采用了另一种不同的方法。
Lomont 也发现 i = 0x5f3759df - ( i >> 1 ) 实为 $1 \over {\sqrt x}$ 的粗略逼近,但他没有深究这个式子背后的数学含义,而是将此常数泛化为一个变量 $R$,通过最小化其与 $1 \over {\sqrt x}$ 的误差,反解出常数 $R$,其中运用的一些技巧值得品味。
有趣的是,他在论文中提供了另一个他认为最佳的常数 5f375a86,并通过实测证实了他的想法。但此常数只是以毫厘之差险胜原算法(一次迭代 $0.175228$ vs $0.175124$,二次迭代 $4.66 \times 10^{-4}$ vs $4.65437 \times 10^{-4}$)。Lomont 在论文中表达了他的惊讶,这个实验同时也使那位不知名的作者(传闻说是 Quake 的作者 Carmack,然而他自己不承认)更加扑朔迷离。
总结 & 推广
这个算法的核心其实很简单:先使用某种手段近似估计解,再用牛顿法迭代增加精确度。同时,它也启示我们: 浮点数表示和对数之间存在某种联系,而对数恰是我们简化计算的利器。
按照这个思路,我们可以拓展出立方根倒数的对应算法,也可以将 32 位算法改写为 64 位(Lomont 在他的论文中提供了 64 位的常数 0x5fe6ec85e7de30da)。现如今,这些算法的加速效应已经不太明显了,但深入剖析上古神话背后的理论,也未尝不是件有趣的事。
也许 他真的是神
参考文献
作者:hsfzxjy
链接:
许可:CC BY-NC-ND 4.0.
著作权归作者所有。本文不允许被用作商业用途,非商业转载请注明出处。

OOPS!
A comment box should be right here...But it was gone due to network issues :-(If you want to leave comments, make sure you have access to disqus.com.